我院“自然语言处理与智能软件技术”研究团队发表“文本自动摘要”研究最新成果
华南师范大学软件学院/新闻通知2020-03-08 14:17:41来源:华南师范大学评论:0点击:收藏本文
2020年3月2日,华南师范大学软件学院“自然语言处理与智能软件技术”研究团队在团队负责人曾碧卿教授带领下,再次在《Applied Sciences》上发表最新研究成果论文,论文题目是《Comprehensive Document Summarization with Refined Self-Matching Mechanism》,论文作者包括有:曾碧卿、计算机学院徐如阳、杨恒、周武等三位硕士研究生、以及软件学院研究生甘子邦。《Applied Sciences》是中科院学术期刊分区表中的SCI三区期刊,影响因子2.217。
该论文研究了抽取式自动文本摘要系统,通过深入研究,提出了一种优化的自匹配机制,用以提升模型概括文本语义的能力。
研究自动摘要系统的目的是压缩文本,在理解原文本的基础上,提炼简洁、扼要的文字摘要。随着经济社会中信息技术的广泛应用,在各个领域,文本资源都在不断地增加,对自动摘要系统的实际需求也在不断增长。文本摘要方法可分为两类:生成式方法和抽取式方法。抽取式方法从源文档中选择包含突出信息的句子组成摘要,生成式方法以序列到序列模型为基础,逐个生成单词构成摘要。
该论文的贡献主要有3点:(1)针对长文档中,模型因难以保留时间步间隔较远语句的信息,导致关键信息的丢失问题,在抽取式的摘要系统中,融入自匹配机制,通过自匹配机制,来动态地为文中的每个单词和句子聚集相关的全局信息,建立长期依赖关系,缓解模型记忆问题。(2)通过高斯偏差为局部信息建模,并融合进原始的注意力分布中,以提升局部上下文的语境表征(如短语结构等)。(3)在解码时刻,利用指针机制,使得解码器能够综合当前抽取状态、之前决策的相对重要性增益来选择句子。
因此,该论文不仅在实验结果上具有统计意义,也为类似自动摘要技术带来新的解决思路。
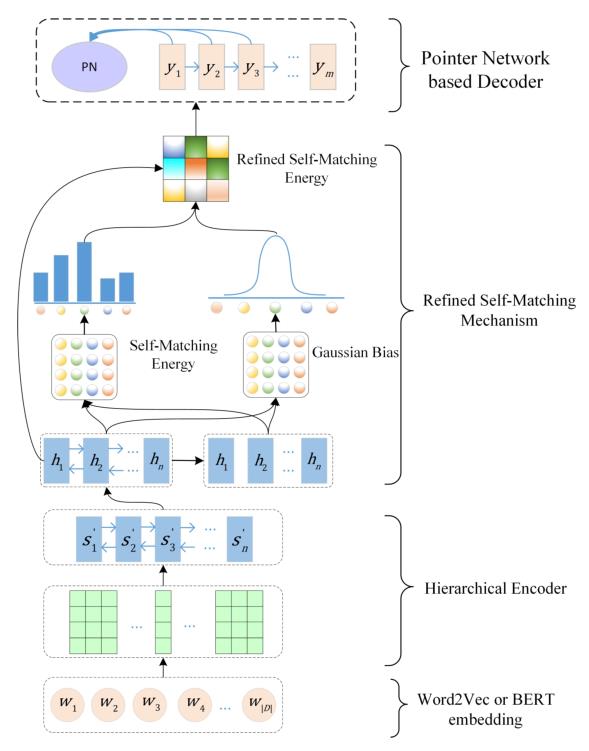
基于优化自匹配机制的全局文档摘要模型图
《Applied Sciences》学术期刊的影响因子2.217
拟稿:徐如阳
审稿:陈锦辉
标签:#研究最新成果
